
ASR&SD挑戰賽正式打響 基線系統和開發訓練集發布
發布時間 : 2021-08-09 閱讀量 : 2413

在數字經濟快速發展的時代,數據成為生產要素,算力成為重要生產力,推動各大行業數字化轉型和生產力變革。以數據、算法和算力“三駕馬車”驅動的人工智能,正在改變基礎學科和各個行業的創新模式。鼓勵AI開發者積極創新,引領時代發展,是應對未來社會變革的必然要求。
由北京Magic Data、中科院聲學所和江蘇師范大學主辦,MagicHub.io開源社區、上海白玉蘭開源開放研究院、華為MindSpore社區、英特爾OpenVINO中文社區協辦的“對話式AI語音識別及說話人識別(ASR&SD)挑戰賽”自開展以來已經收到四十多個來自各大高校和企業參賽隊伍注冊報名。報名通道于8月6日關閉,主辦方正式開啟下一階段的賽程,8與7日正式向參賽隊伍開放開發訓練集和基線系統。
開發訓練集
主辦方針對賽道一“對話場景下的語音識別(ASR)準確率”和賽道二“對話場景下的說話人識別(Speaker Diarization)準確率”開放了以下訓練數據集: 1.160小時中文對話數據,主辦方通過郵件形式將下載鏈接發送到參賽者郵箱,下載時間為8月7日~8月9日24時止,請參賽者及時查收和下載。 2.MagicData開源的755小時ASR中文朗讀數據,請參賽者登錄MagicHub.io開源社區并注冊社區賬號進行數據集下載,下載地址為:https://magichub.io/cn/datasets/mandarin-chinese-scripted-speech-corpus-daily-use-sentence-command-and-query-sms/ 3.此外,賽道二SD賽道允許使用兩個開源數據集:[VoxCeleb Data (openslr-49)],下載鏈接:http://www.openslr.org/49/和[CN-Celeb Corpus (openslr-82)] ,下載鏈接:http://www.openslr.org/82/供參賽者使用。
基線系統介紹
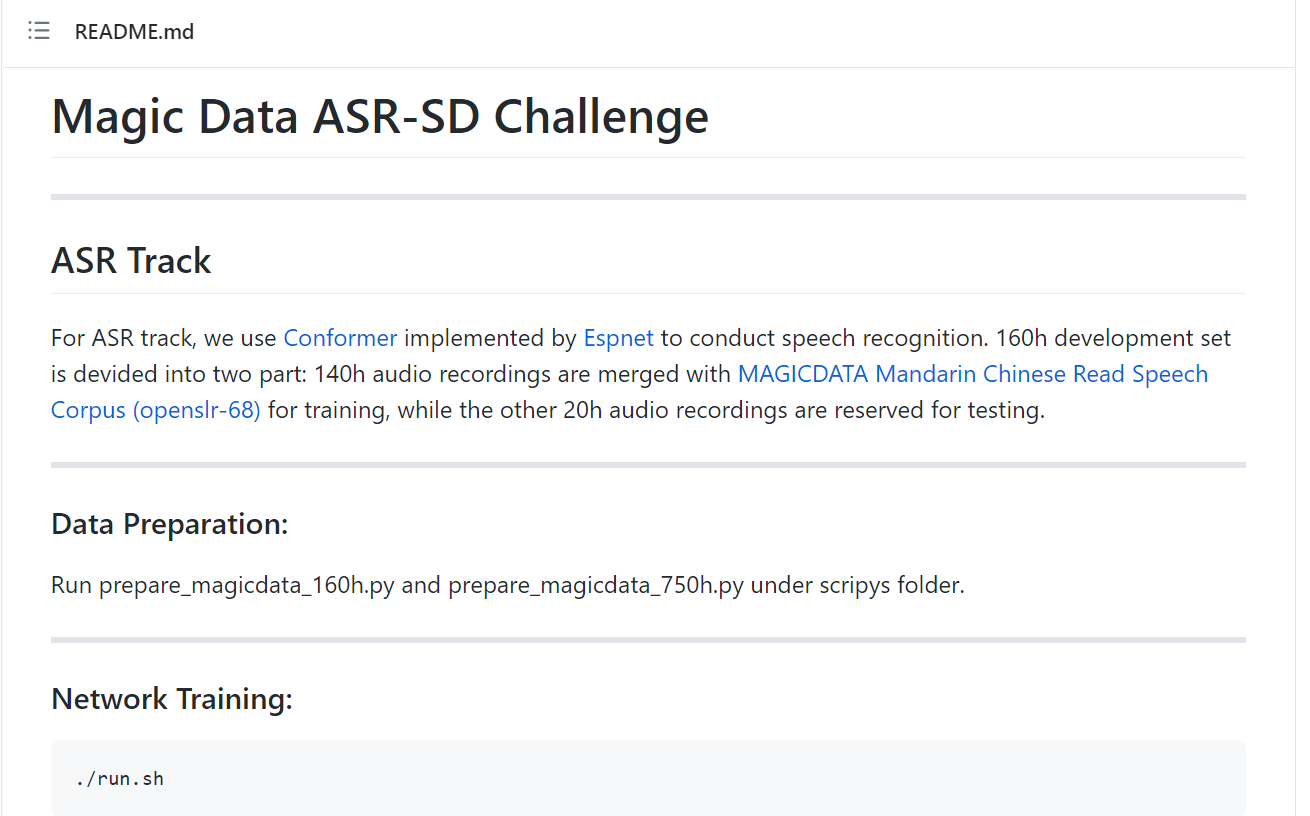
GitHub上基線系統教程
為了幫助參賽者快速、高質量完成模型開發和訓練,主辦方提供了基線系統,提供給參賽者使用。 我們基于 kaldi 與 espnet 等開源工具與項目搭建了簡易的基線系統,賽道一ASR 賽道的基線系統我們使用了端到端系統,用 Conformer 對北京Magic Data提供的160小時中文對話數據和開源的755小時ASR中文朗讀數據進行了訓練。 賽道二SD賽道上,我們使用了 VBHMM-XVector 系統,訓練時加入了 VoxCeleb 與 CN-Celeb 數據集,從而實現說話人特征的提取。詳細的使用教程請見 :https://github.com/MagicHub-io/Magic-Data-ASR-SD-Challenge
基線系統答疑指導
參賽者在比賽過程中,對基線系統有任何問題,可在以下鏈接中提交:https://github.com/MagicHub-io/Magic-Data-ASR-SD-Challenge/issues,將有專家團隊給予解答。
競賽主委會支持團隊
參賽者在挑戰賽中遇到相關問題,可通過發送郵件至ncmmsc16th@163.com郵箱,郵件標題為“ASR&SD挑戰賽疑問”,由組委會的以下資深技術專家提供專業技術問答和指導:
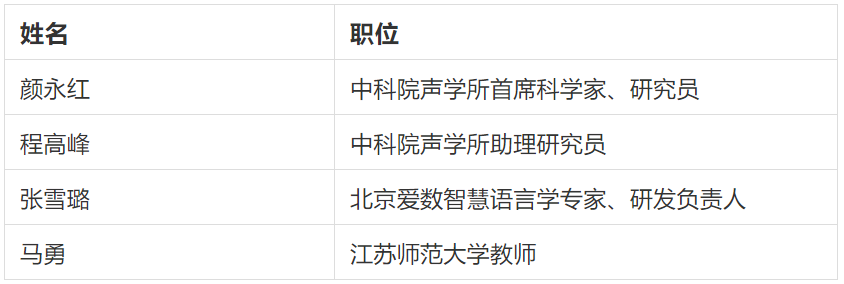
競賽主委會支持團隊
指導專家們均是在語音界積累豐富的研究和實戰經驗,在他們的指導下,相信會給參賽者帶來不少啟發。